Introduction
Links to documentation:
- vSphere 8.0 Update 3 Release Notes for ESXi https://docs.vmware.com/en/VMware-vSphere/8.0/rn/vsphere-esxi-803-release-notes/index.html
- vSphere 8.0 Update 3 Release Notes for vCenter https://docs.vmware.com/en/VMware-vSphere/8.0/rn/vsphere-vcenter-server-803-release-notes/index.html
VMware vSphere 8 Update 3 brings a host of new features and enhancements designed to improve performance, security, and operational efficiency. This article provides an in-depth look at the latest updates and how they can benefit your IT infrastructure.
- Lifecycle Management Enhancements
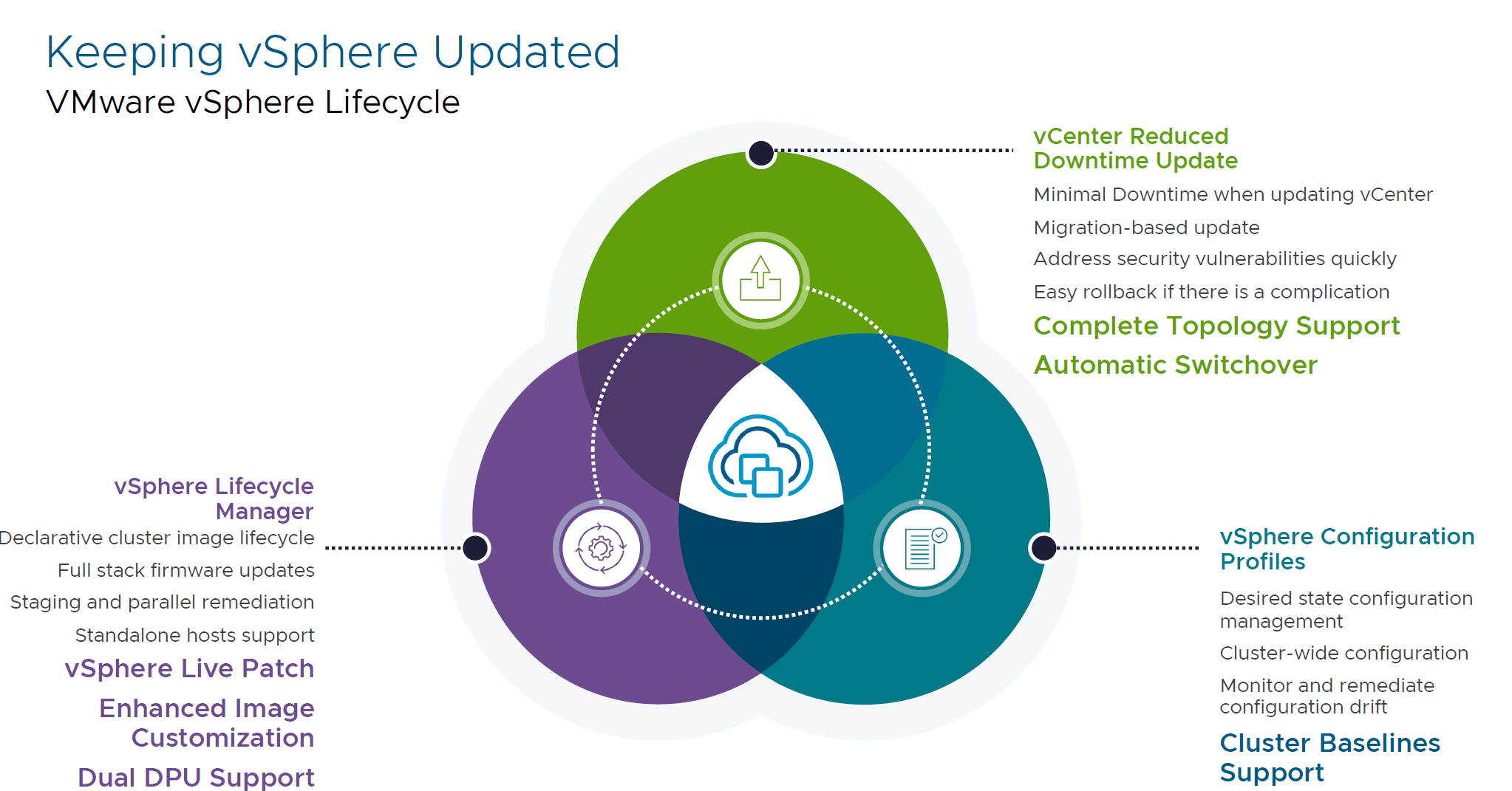
- vCenter Reduced Downtime Update
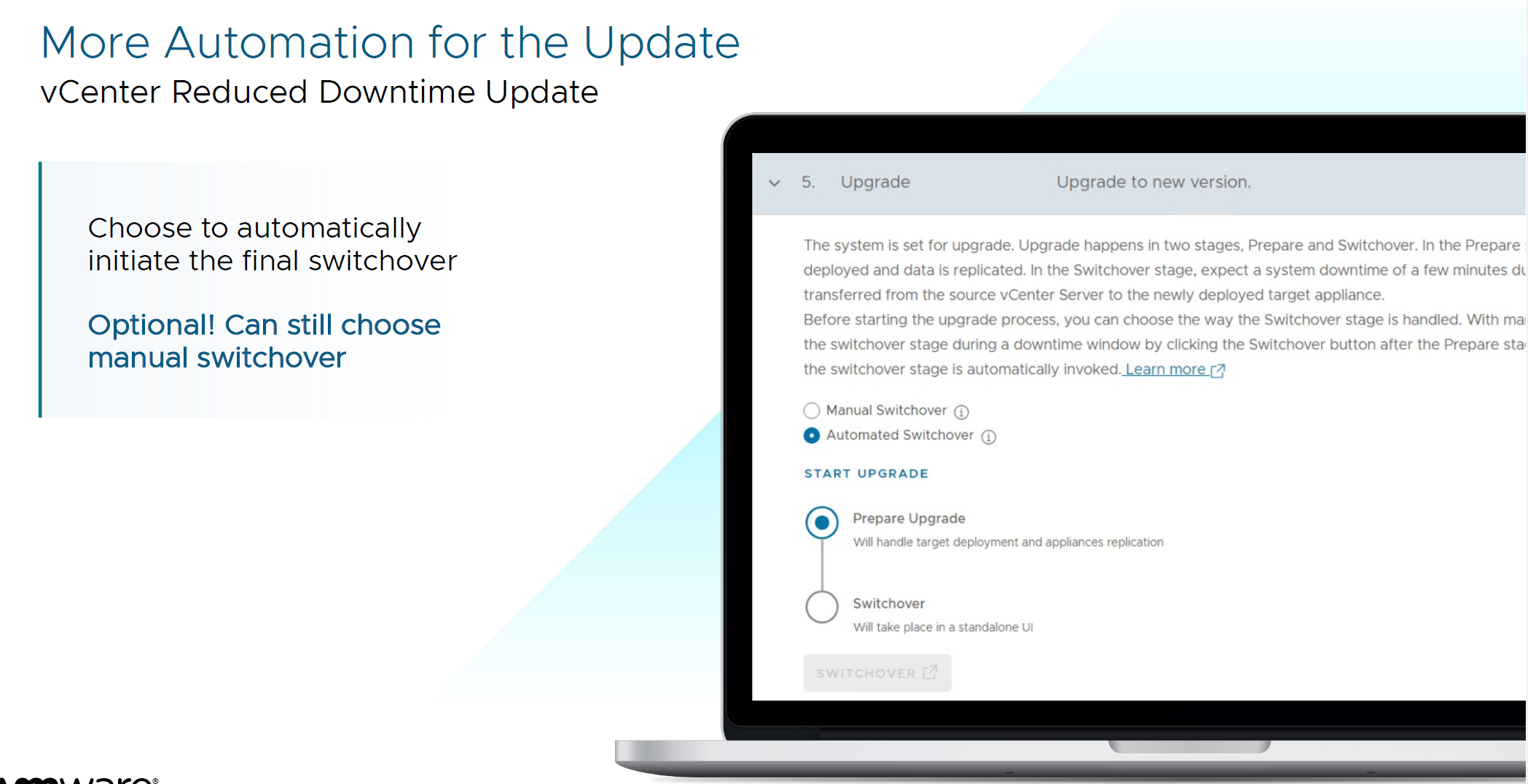
Minimal downtime when updating vCenter. You can quickly address security vulnerabilities and easily rollback if complications arise.

Previously it was limited to single self-managed vCenters, but not it is available for all vCenter topologies.
And administrators now have an option to do manual or automated switchover. Before that, it was only manual switchover.
- Partial Maintenance Mode
It is a state that ESXi will be placed into where VMs continue to run, disallowing migrations and new VM creations on a host. It is tries to lock down the host in terms of VM mobility and VM creation, but it allows the current work workloads to continue running. Furthermore, it is not a state that use will be able to enter into. Only Lifecycle manager will automatically place the host into Partial Maintenance mode when it is performing Live Patching. User have an option to move the host out of Partial Maintenance mode when something goes wrong.

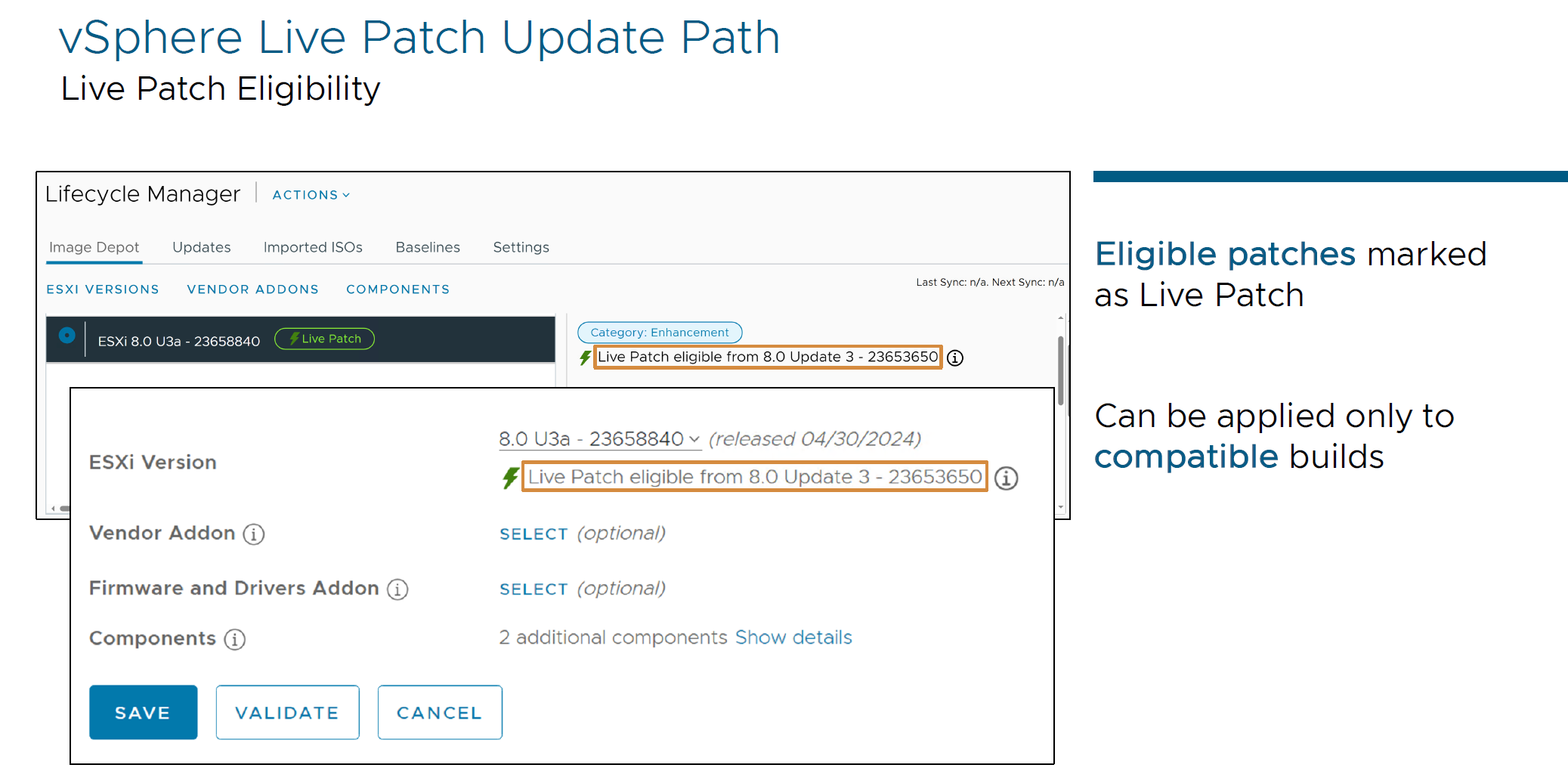
- vSphere Live Patch
Reduces downtime and maintains continuous operation - apply patches without rebooting hosts.
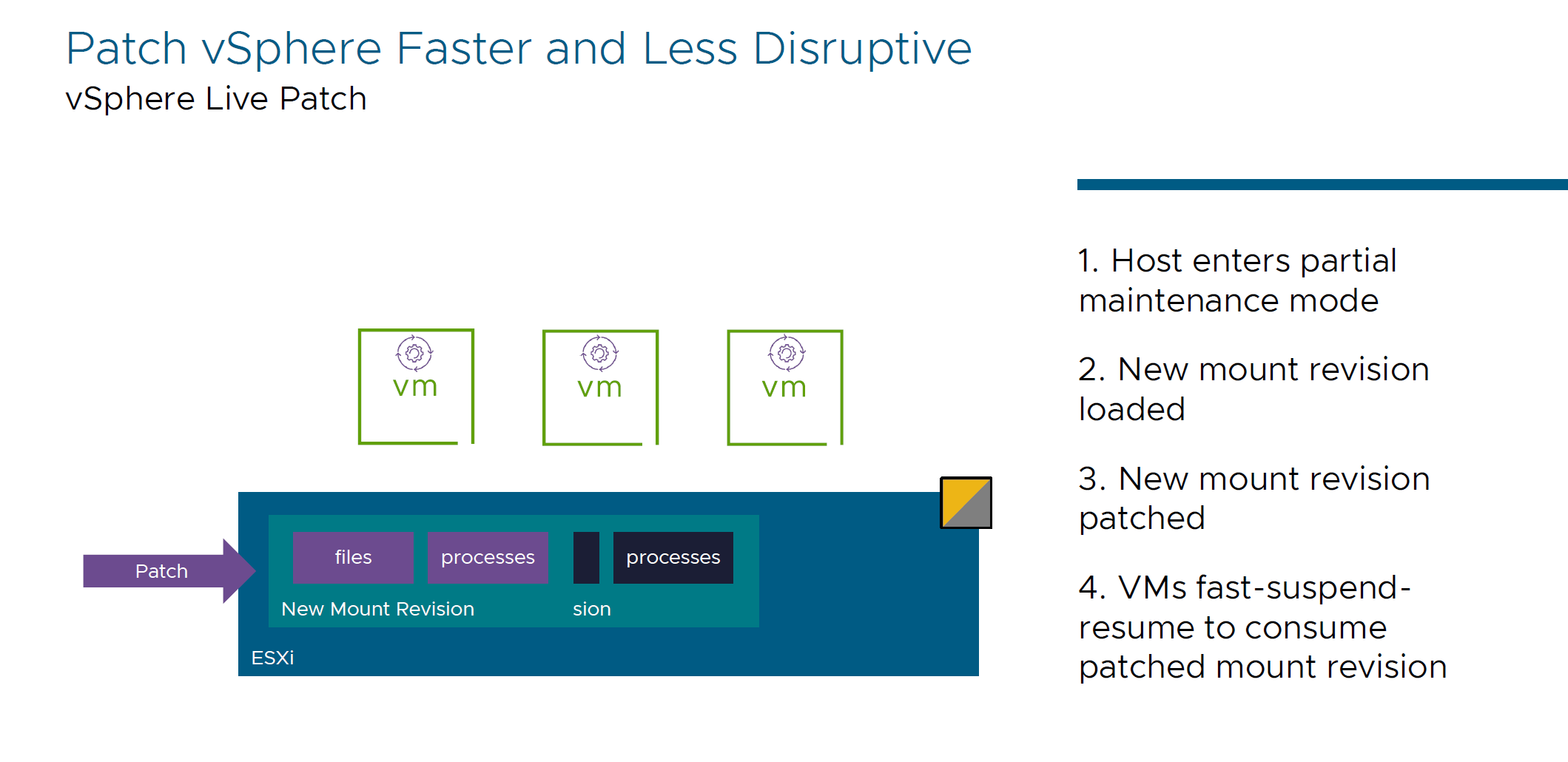
Technical details of that process:
- We're moving host to the partial Maintenance mode
- We mount a new copy (clone / new mount provision) of the area of ESXi host that we want to patch.
- Patching a newly mounted area.
- VMs take advantage of newly patched instance and go through Fast Suspend Resume (FSR). This is the same process as VM configuration (adding a NIC, Hard Disk, etc) and this process is not disruptive.
- When a host is patched, it will be automatically moved out of Partial Maintenance mode.
FSR is not available for VMs that configured with Fault Tolerance and Direct Access devices.
But GPU enabled VMs are supported!
- Enhanced Image Customization
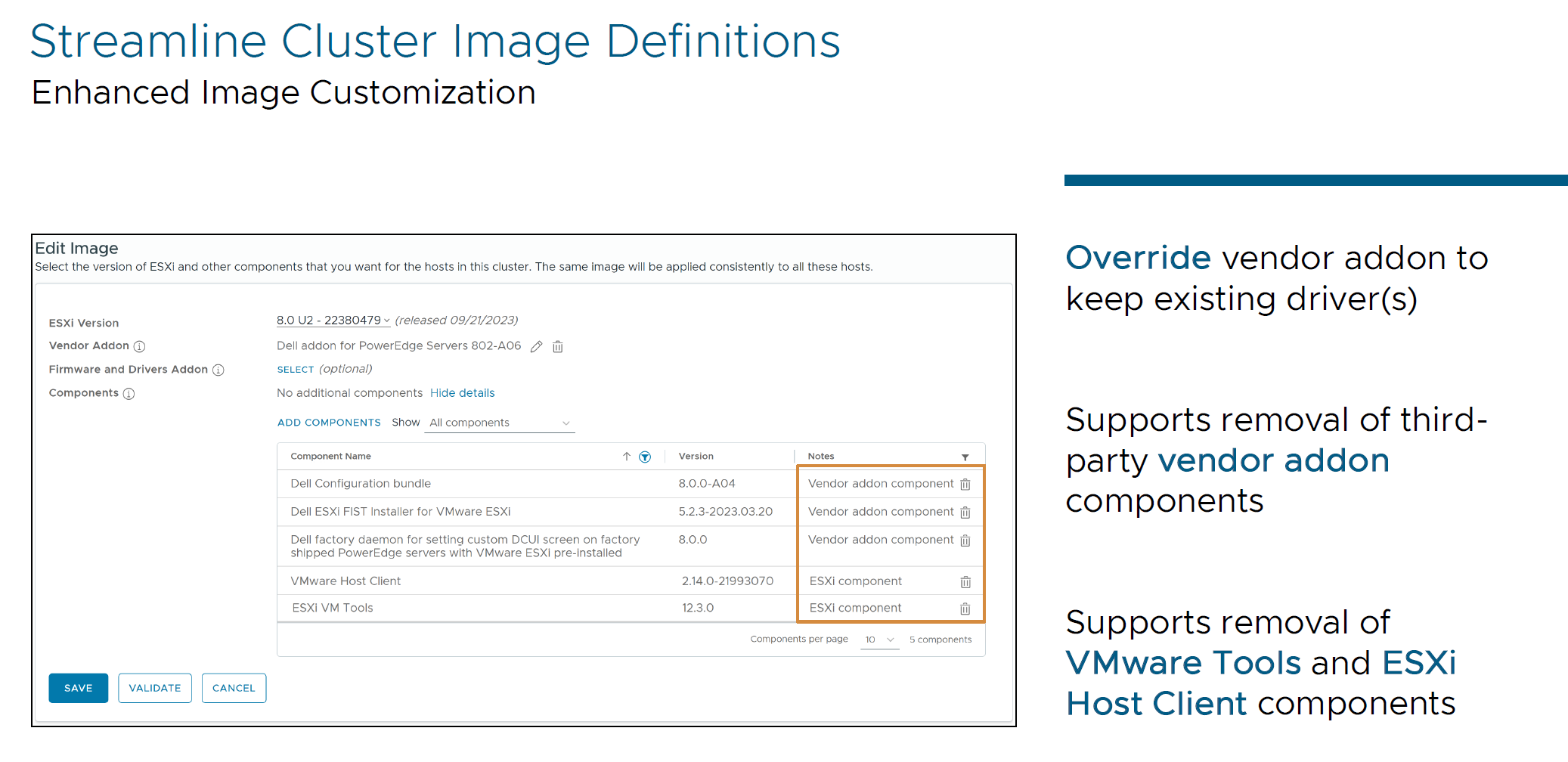
Streamlines cluster image definitions and maintains compatibility and customization, and you can override vendor add-ons and remove third-party components. Sometimes, it is useful to override some components that vendor is recommends to apply to the images or use older drivers for compatibility and stability. To decrease size of image for Locations with tiny network bandwidth, you can remove VMware Tools or some of the Host Client components.
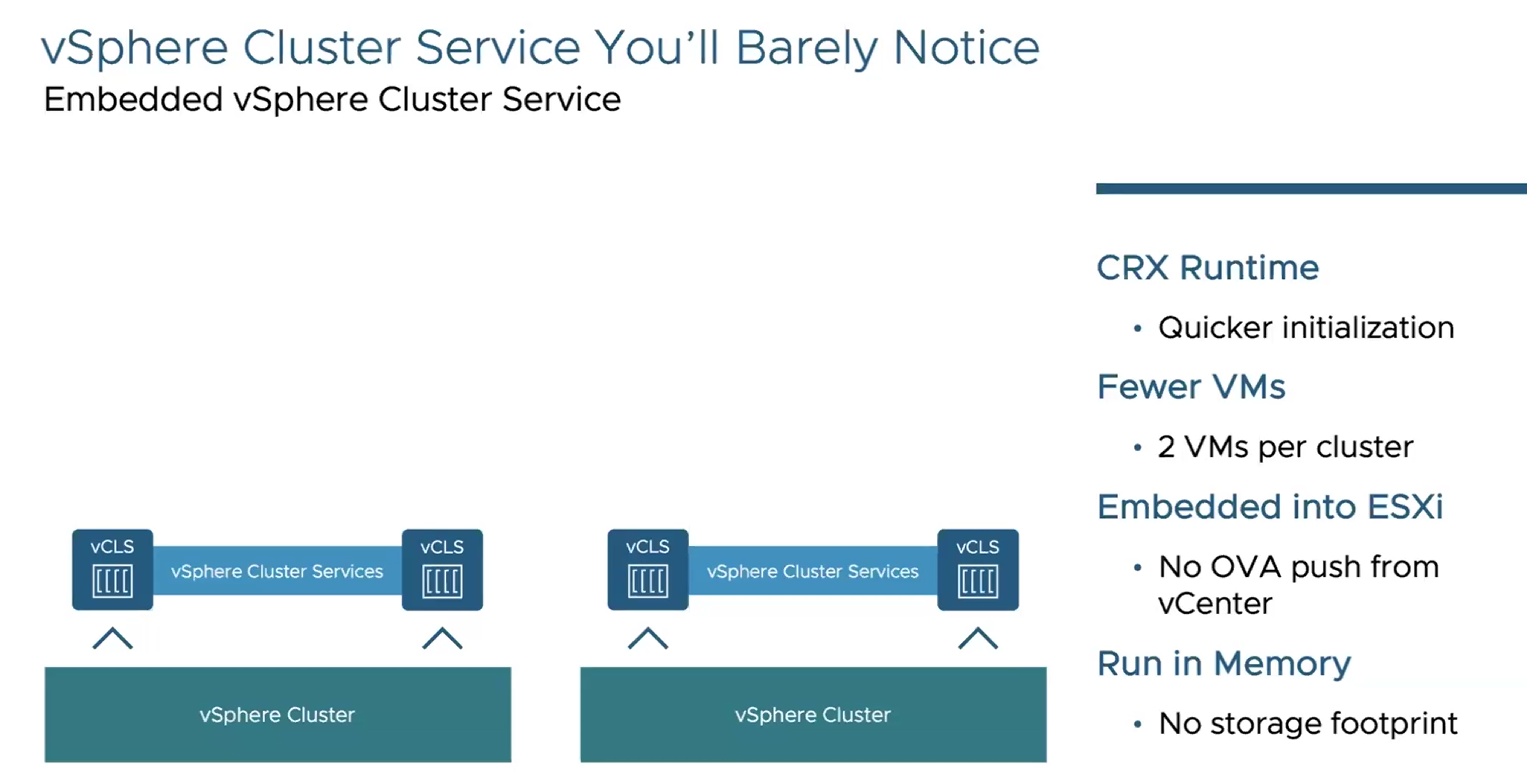
- vSphere Cluster Service changes
Now, vCLS service objects are no longer traditional VMs - they are now based on CRX runtime. Now only 2 vCLS appliances running per cluster and they are embedded to ESXi directly! No OVA push and problems with that! Memory footprint around 100Mb per appliance = 200Mb per cluster.
- Storage Enhancements
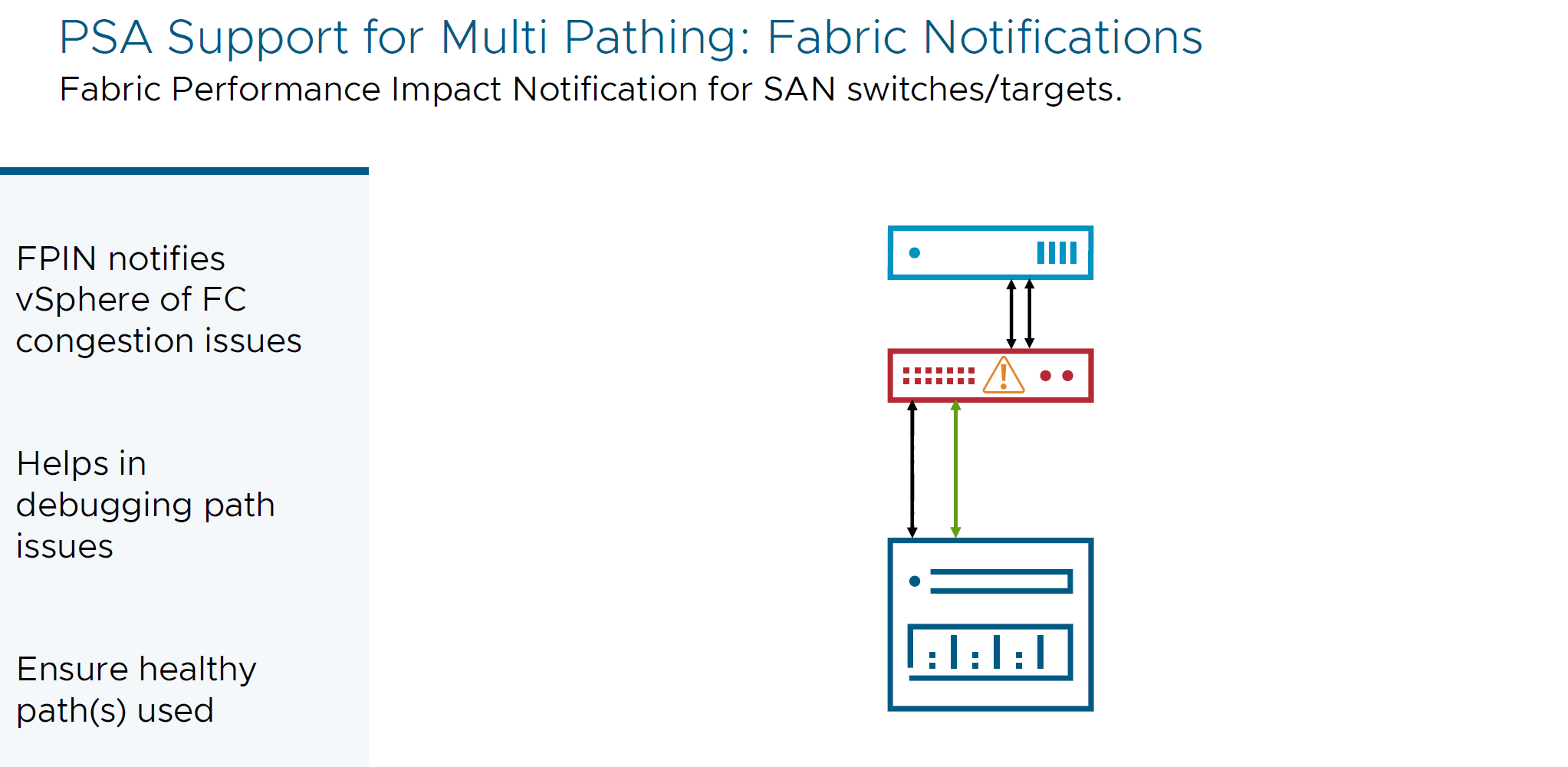
- Fabric Performance Impact Notifications (FPIN)
With FPIN vSphere infrastructure layer now can handle notifications from SAN switches or targets, learn about degraded SAN links to make sure to use healthy paths to the storage devices. FPIN is an industry standard that provides notification to the devices of the link or other issues with connection or a possible a path through the fabric.
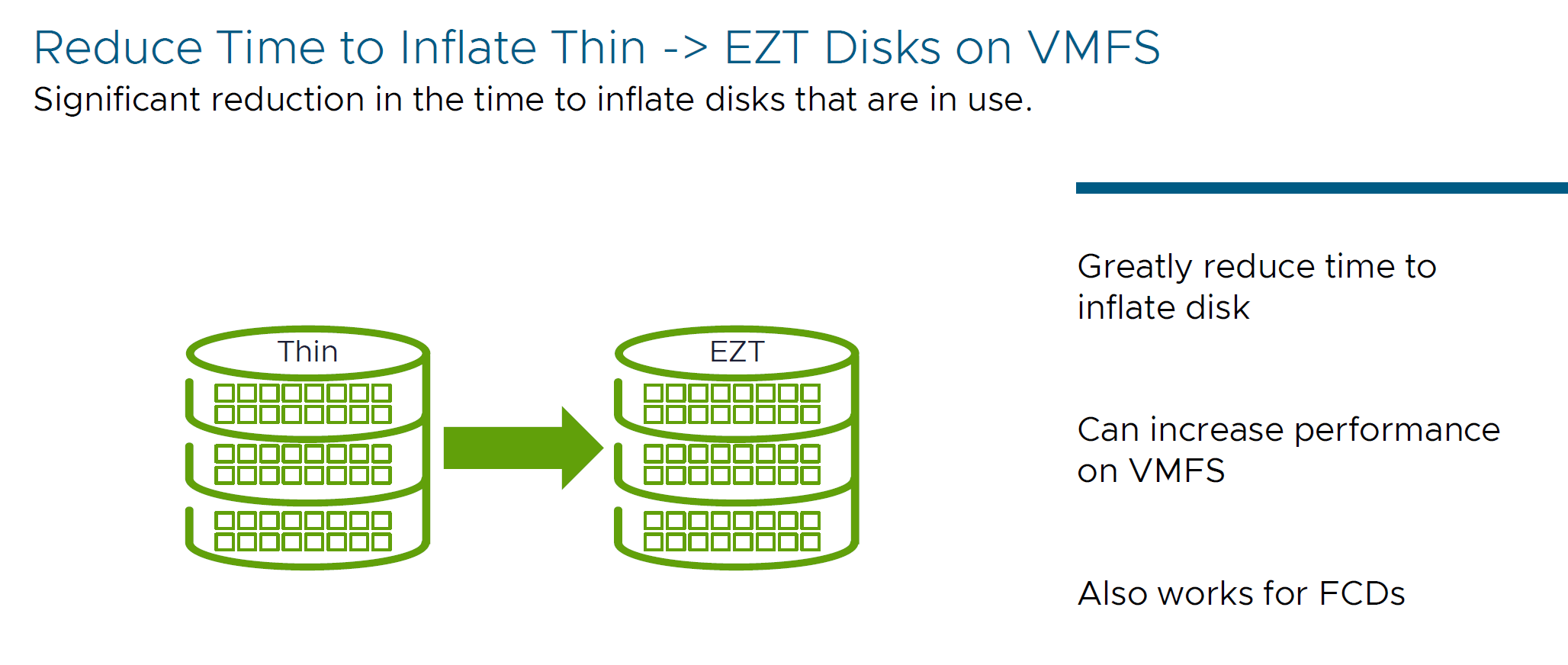
- Inflation mechanism for disks that are in use
New VMFS API calls has been implemented to allow for the inflation of the blocks on VMFS disk while disk is in use. This API is 10x faster than existing Eager Zero Thick disks on VMFS (Thin → EZT). Thick Provision Lazy Zeroed / Thick Provisioning Eager Zeroed and First Class Disks (FCD) now can be inflated in much faster times.
- Support for vVols Stretched Storage Cluster
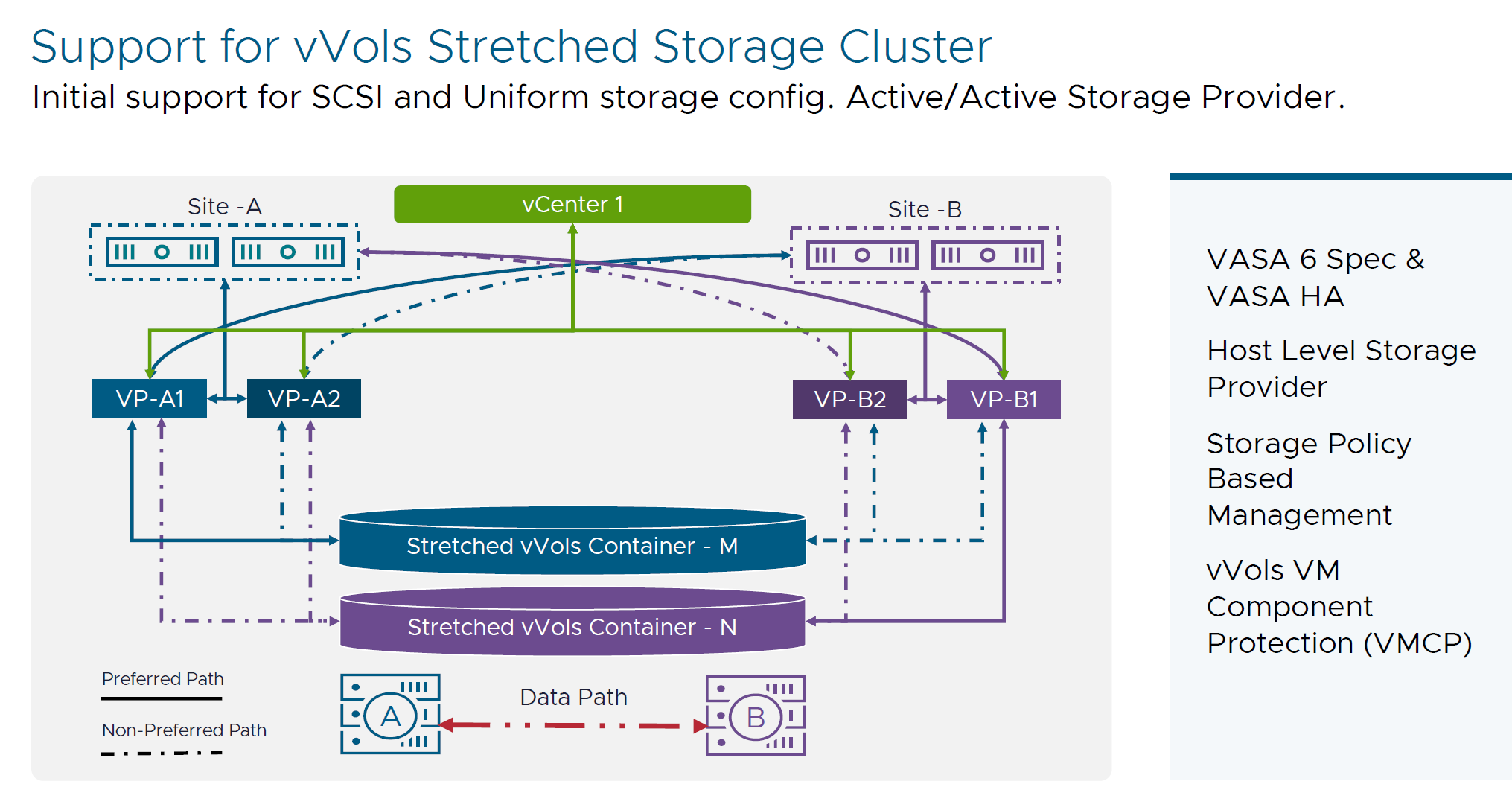
Initial support for SCSI and uniform storage configurations - provides active/active storage provider capabilities for both stretched and non-stretched storage clusters. This will enable vVols to support A-A deployment topologies, or iSCSI block based / FC / iSCSI access between 2 sites.
Pure Storage is design partner for that solution.
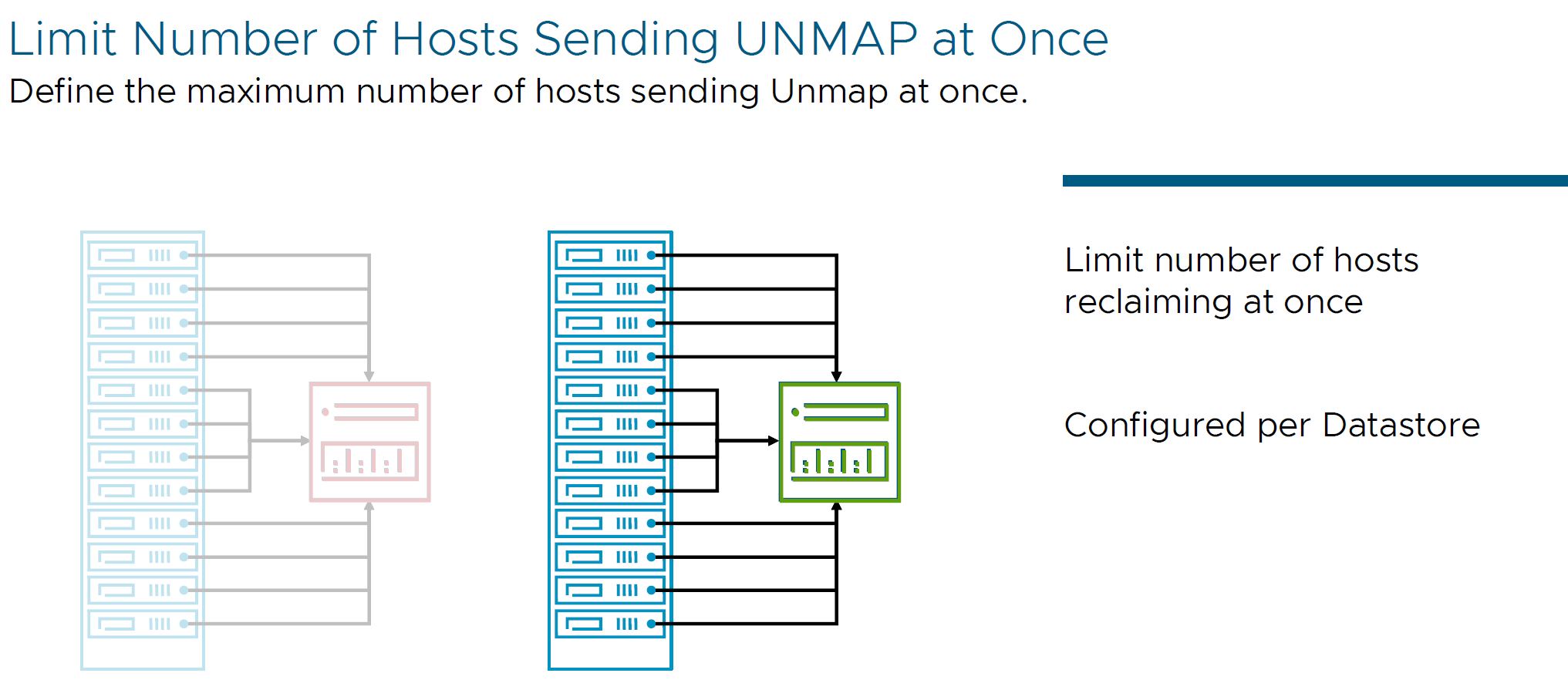
- UNMAP command
Also, 8.0 U3 now have manual CLI and automatic UNMAP support for vVols on NVMe volumes. This allows you to maintain space efficiency without admin intervention. Also, for mitigation of the space reclamation of the array with that amount of traffic with UNMAP commands, the newest version has a definition of maximum number of hosts sending Unmap at once, and it is configured per Datastore (using parameter called reclaim-maxhosts in between 1 and 128 hosts).
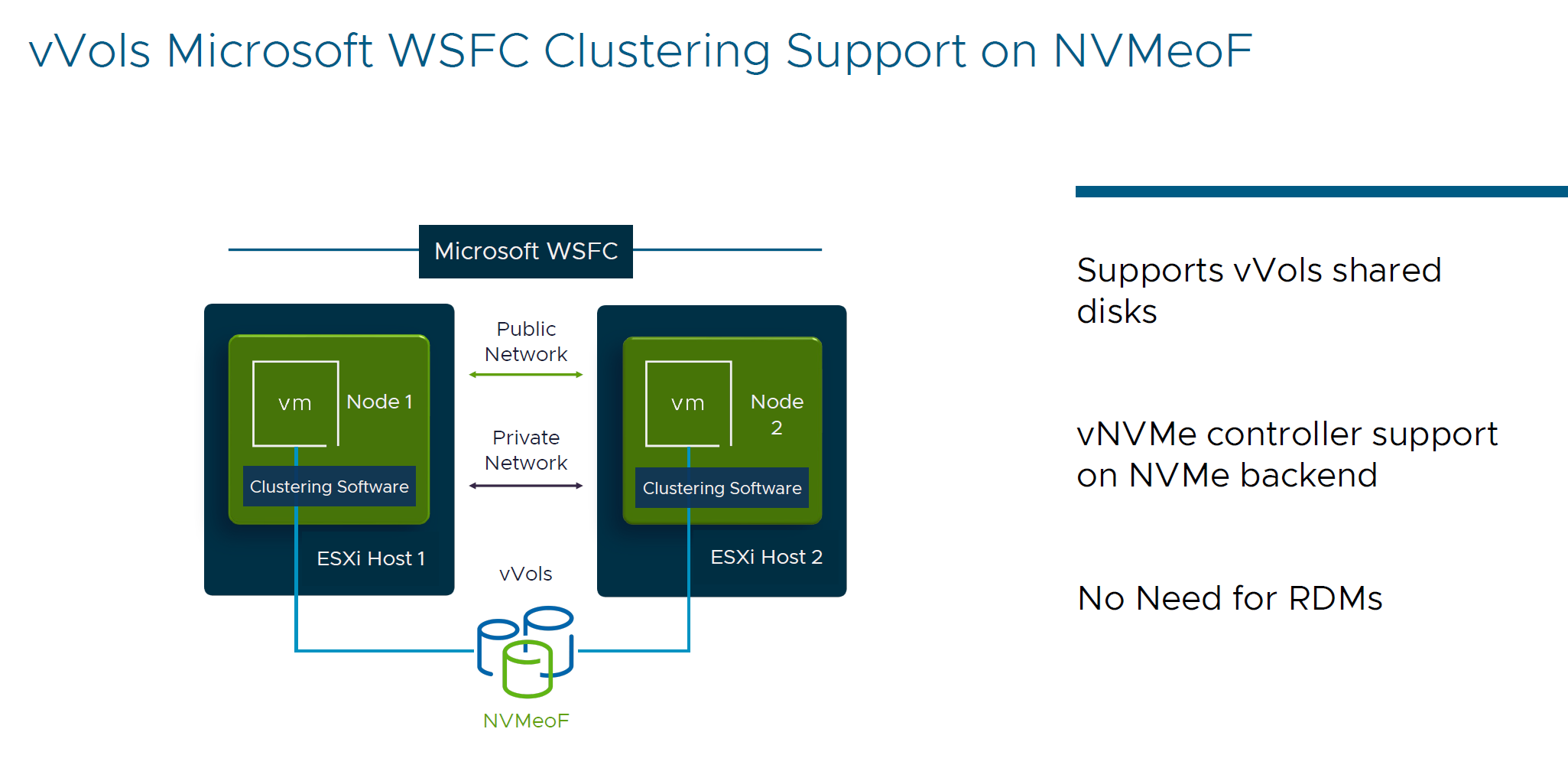
- vVols iSCSI Persistent reservations over NVMeoF
That means that MS WSFC supported within vVols shared disks and no need for RDMs.
- GPU Profiles in vSphere 8
Now Hosts can have different types of workloads on a single GPU and share GPU resources among various applications. Now you can mix and match vGPU profile type, the memory sizes across different VMs leveraging the same physical GPU.
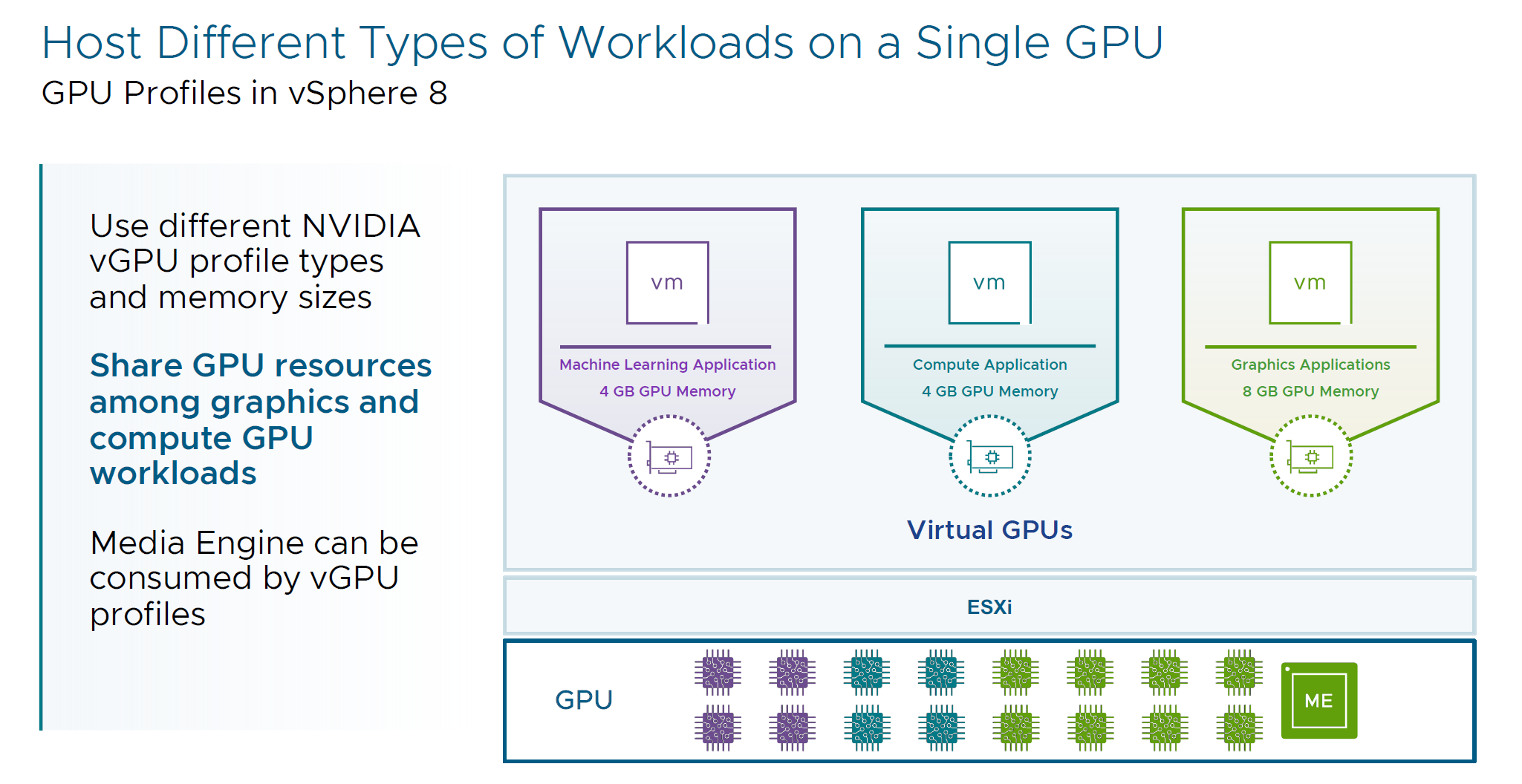
Also, we can leverage a new piece of Hardware called GPU Media Engine. There is typically only one Media Engine per physical GPU and this hardware is designed for things like video rendering (hardware acceleration for H264 / H265 video codecs).
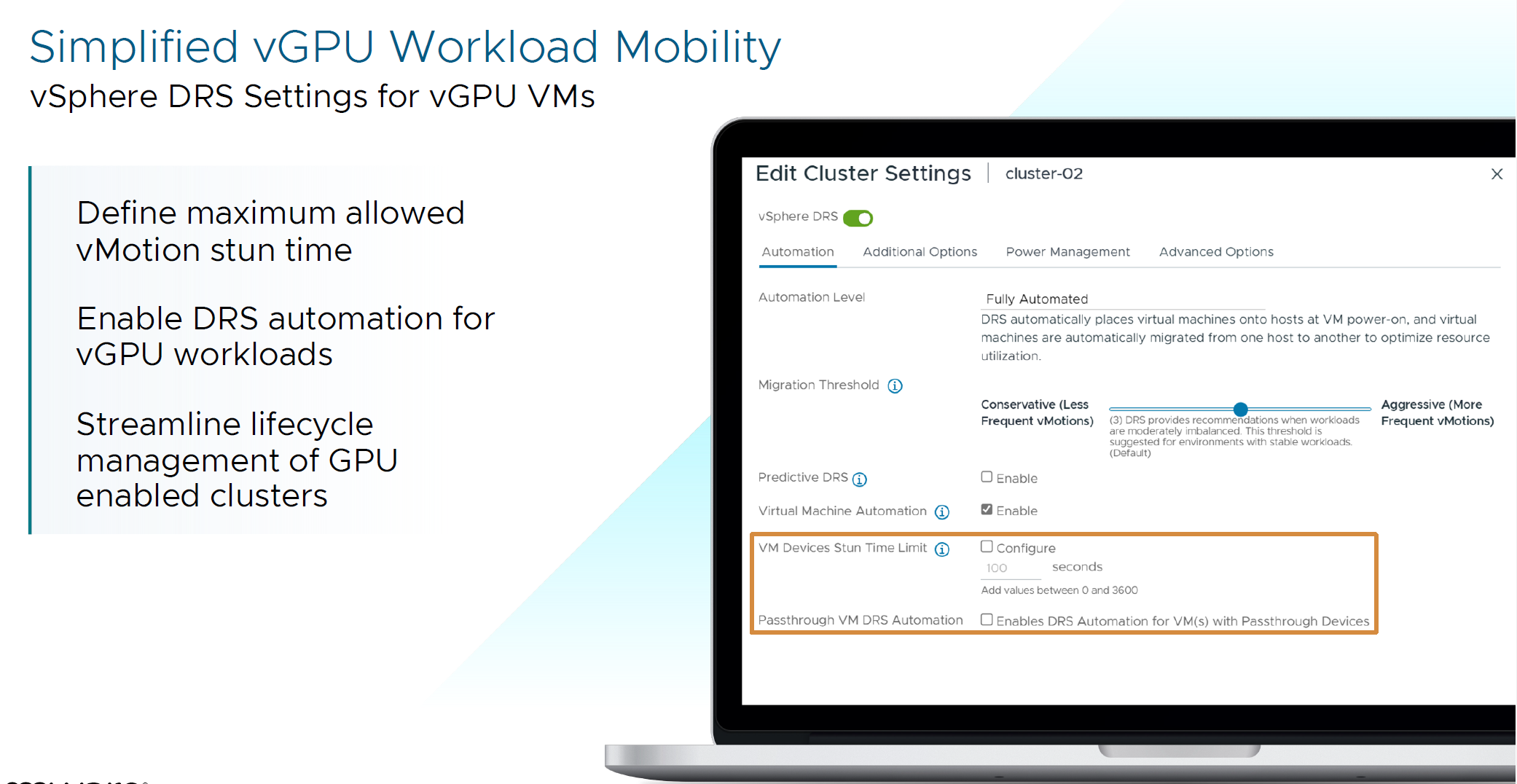
For those devices, vSphere Cluster now has 2 important options with configuring VM Stun time during vMotion and Passthrough VM DRS automation
- Security and Compliance
- PingFederate Support in vSphere Identity Federation

Finally, we now have support for multiple on-premises and cloud IdPs for enabling SSO, MFA, and modern authentication mechanisms and PingFederate is an good start.
- TLS & Cipher Suite Profile Support
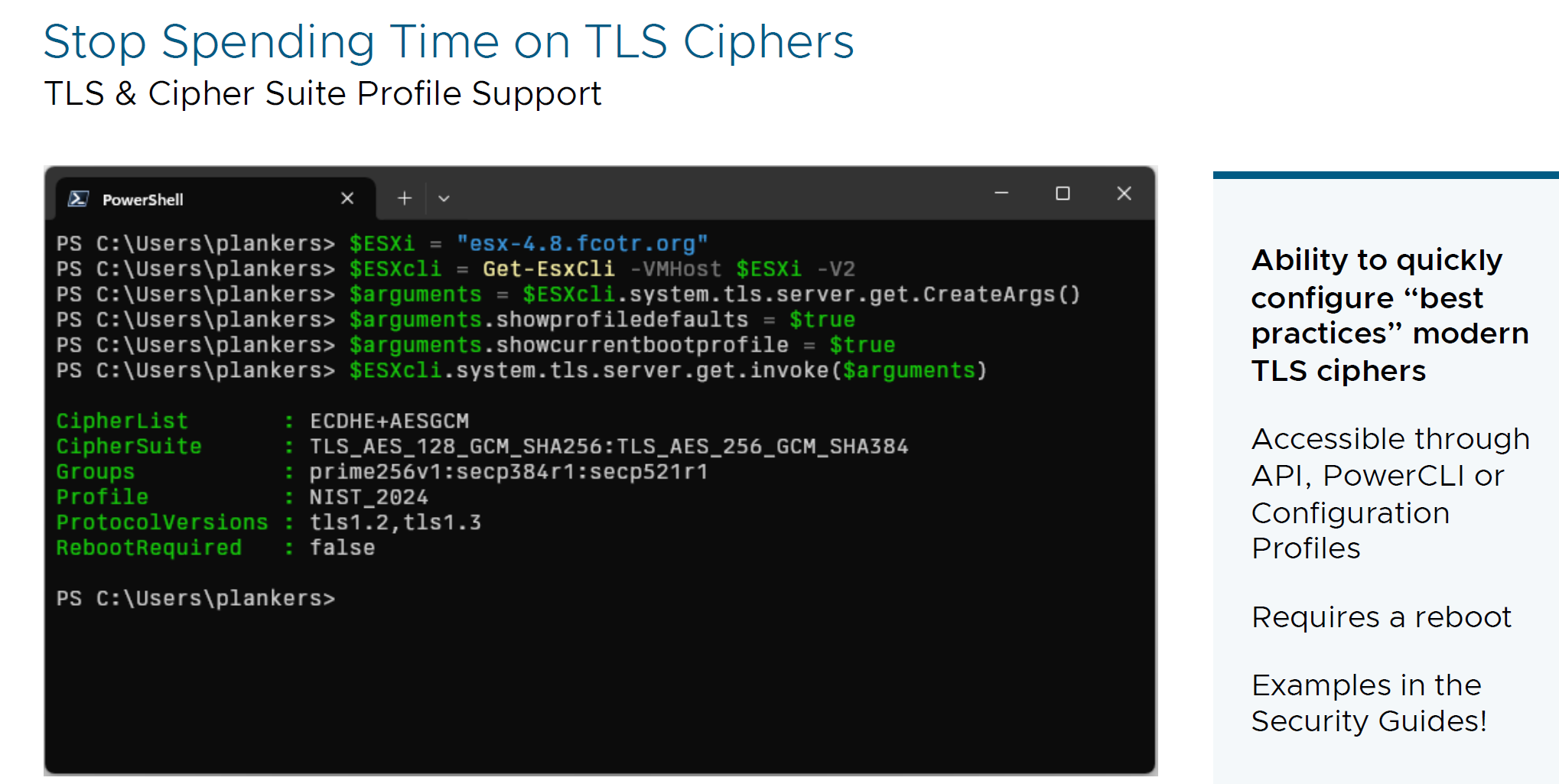
Quickly configure modern TLS ciphers for simplifying configuration of the hosts.
- vSphere IaaS Control Plane / Developer Experience
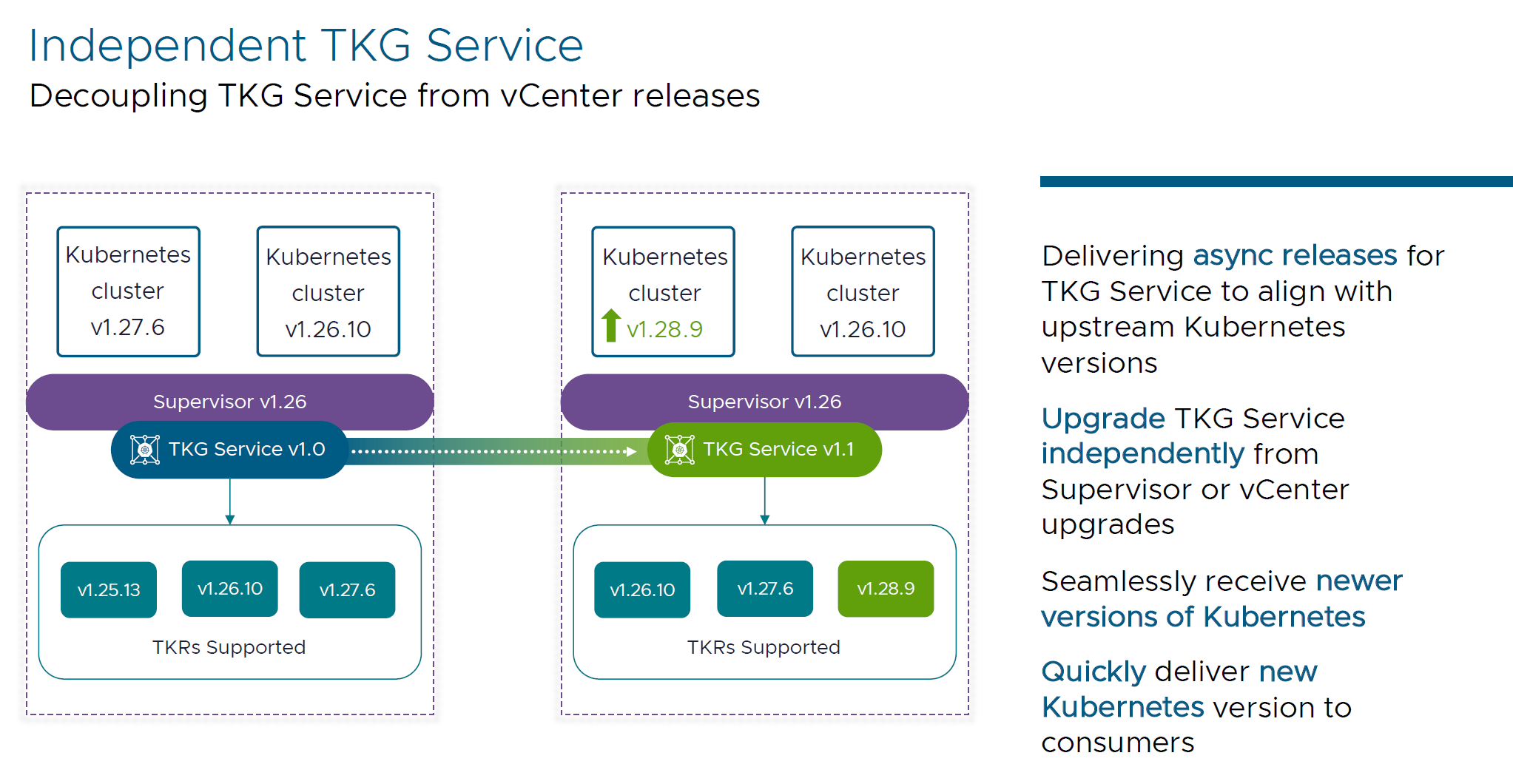
- Decoupling TKG Service: Decoupled updates from vSphere release cycles for greater agility and security.
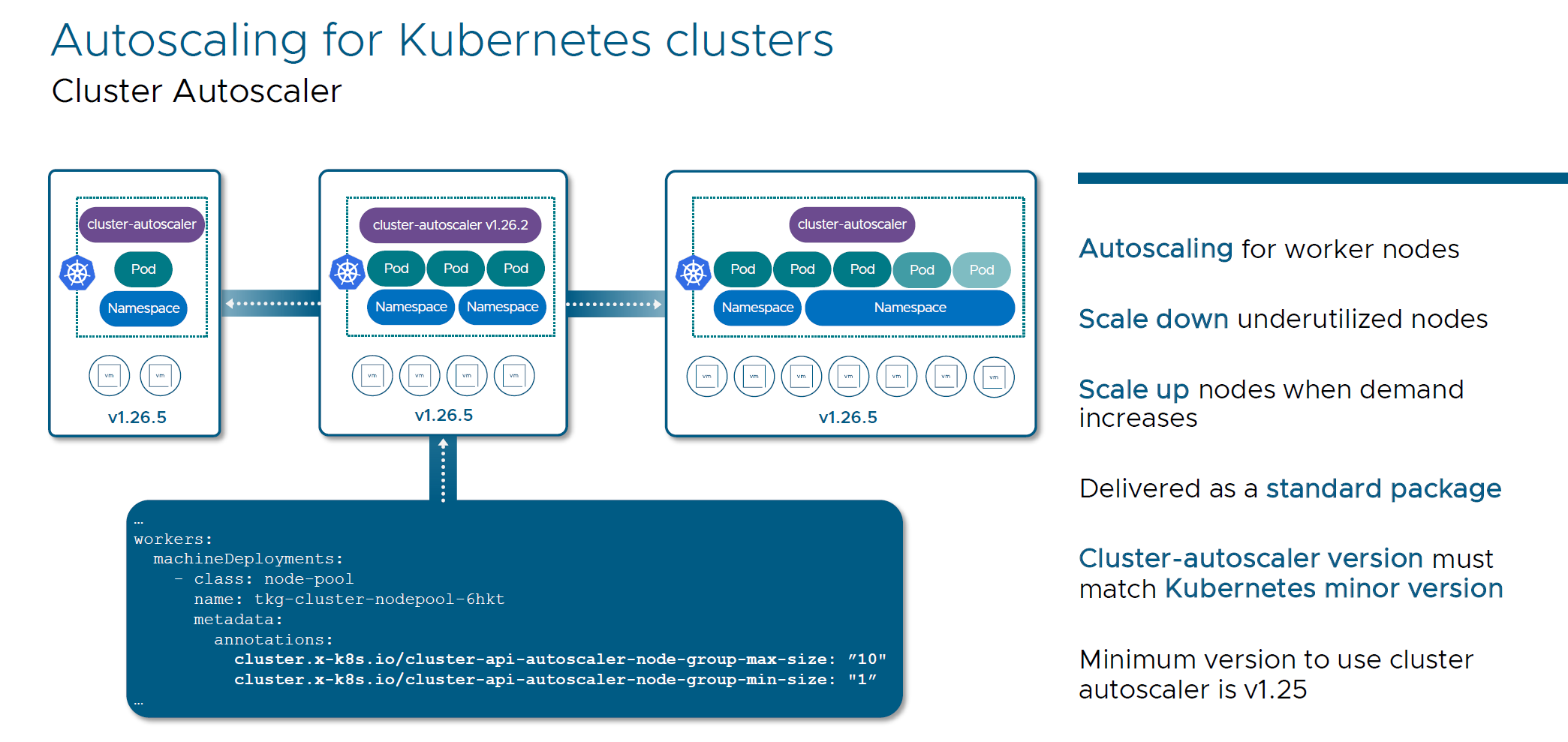
- Autoscaling for Kubernetes Clusters: Scales down underutilized nodes and scales up nodes when demand increases.
- vSAN Stretched Cluster Support: Enhances resilience and disaster recovery capabilities.
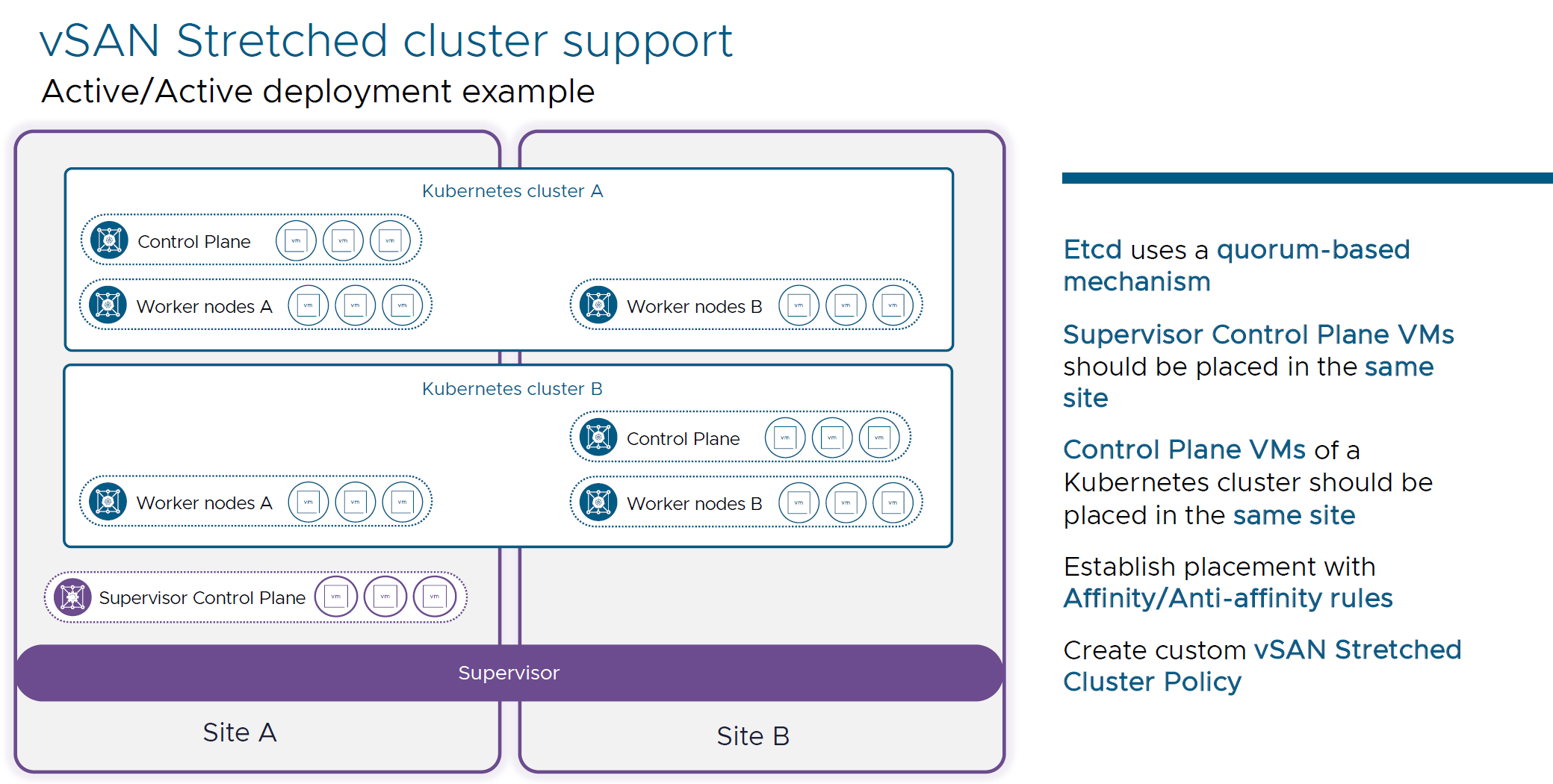
ETCD uses a quorum-based mechanism to ensure data consistency and reliability. This means that a majority of ETCD nodes (a quorum) must agree on any changes before they are applied. This mechanism helps prevent split-brain scenarios and ensures that the data remains consistent across the cluster.
The is no real benefit of spreading a given set of odd numbers of Control Plane VMs across 2 sites for an A-A deployment.
Instead of that, deploy 3 Supervisor Control Plane VMs that will be placed on the same site. And all Control Plane VMs of Kubernetes clusters should also be placed in the same site.
Worker nodes can be spread across 2 sites. For Placement of VMs, you can use Host Affinity rules for each type of VM.
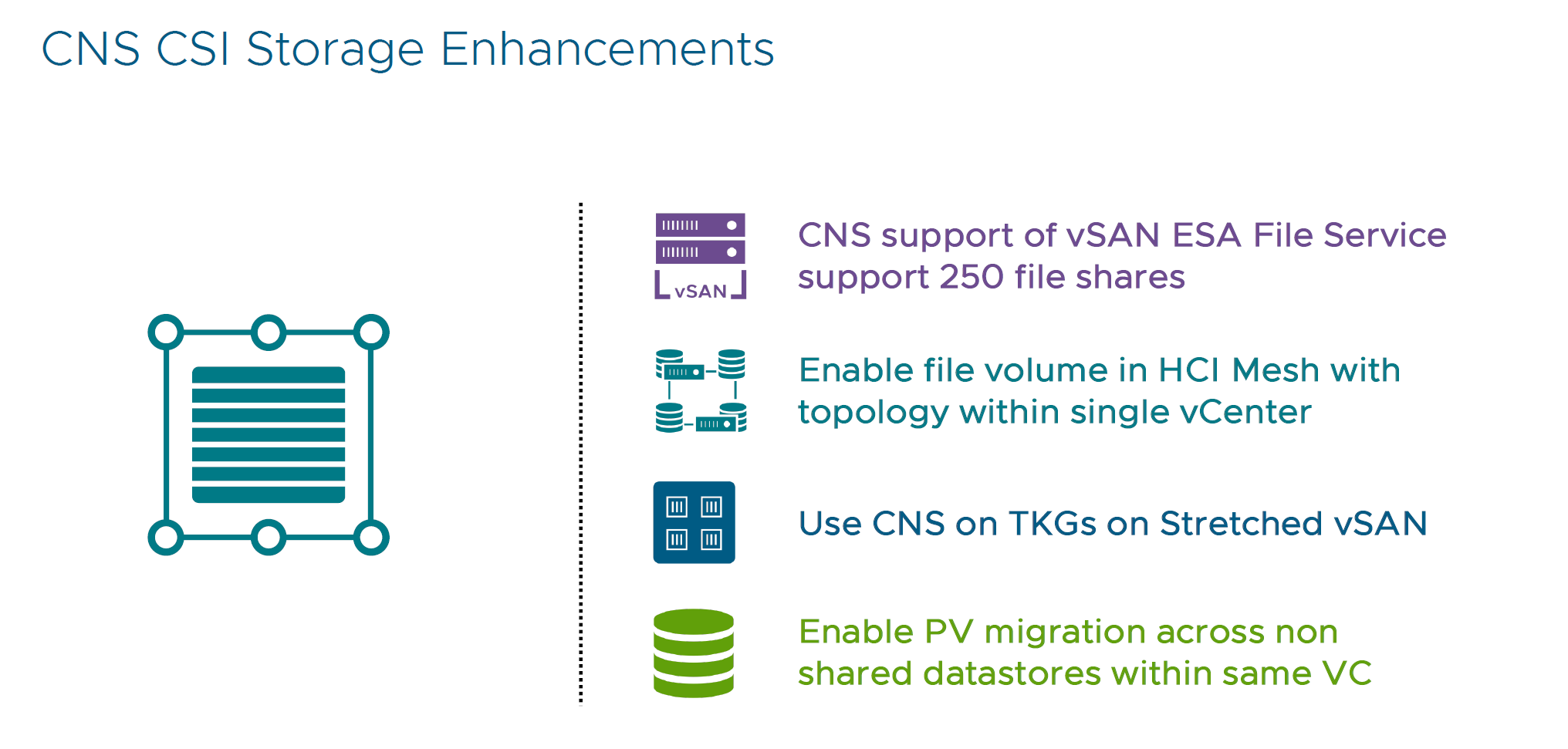
- CNS CSI Storage Enhancements
Increased limits to 250 volumes will help customers with additional file share volumes for Kubernetes Persistent Volumes (PV) or Persistent Volume Claims (PVC).
Conclusion
VMware vSphere 8 Update 3 offers significant improvements in lifecycle management, performance, security, and operational efficiency. These enhancements are designed to help organizations optimize their IT infrastructure and achieve greater agility and reliability.
Comments?
Leave us your opinion.